
2022-12-08
정글에서 살아남기 Week 12
PintOS Virtual Memory(2)
12주차 개발일지
Virtual Memory
가상메모리 추가 과제를 제외한 모든 과제가 끝난 뒤 추가 과제 전 전체 흐름과 함수 작성 시 의문점 들에 대한 정리를 먼저하고자 글을 써본다.
- Memory Management
- Anonymous Page
- Stack Growth
- Memory Mapped Files
- Swap in / out
- Copy on Write
Introduction
가상메모리를 사용하는 이유 In pintos =>실행할 수 있는 프로그램 크기와 수는 메모리에 의에 제한 된다. 이를 해결해 무한하게 사용한다는 착각을 하게끔 만들어준다. (프로세스==스레드 가 메모리 전체를 사용한다는 착각) Wide view => 프로세스별 가상메모리 할당 및 침범불가로 프로세스 간 isolation 구축 => Physical memory 보다 큰 메모리를 사용할 수 있다
Memory Management
SPT
Supplemental page table -> Page fault시 커널이 supplement 페이지 테이블에서 오류가 발생한 가상 페이지를 조회하여 어떤 데이터가 있어야 하는지를 확인할 필요가 있다. -> 프로세스가 종료될 때 커널이 추가 페이지 테이블을 참조하여 어떤 리소스를 free시킬 것인지를 결정한다. void supplemental_page_table_init (struct supplemental_page_table *spt); 1. 새로운 프로세스가 시작할 때 호출되거나 (initd in userprog/process.c ) 2. 프로세스가 fork될 때 호출된다.(__do_fork in userprog.process.c) 가상 주소 va를 hash function을 통해 hash table의 인덱스로 변경하면 해당 인덱스에 매핑되는 bucket에는 hash_elem이 달려있어 이 hash_elem을 통해 해당 페이지를 찾을 수 있는 구조이다. 이때 충돌이 발생하면 동일한 인덱스에 hash_elem을 줄줄이 다는 식이다.
table structure
array - 가장 구현이 간단하나 공간복잡도가 크다는 문제(메모리 용량을 낭비) / 시간복잡도는 O(1) linked list - 탐색 시 시간 복잡도 - O(n) 낭비가 크다. 리스트 역시 심플하긴 하지만, 일일이 확인하면서 찾아야 하기 때문에 시간이 낭비 Hash table - 탐색시 시간복잡도 O(1)이라는 장점이 있으며 array와 달리 연속적인 공간을 쓰는 개념이 아니기에 공간복잡도 측면에서도 효율적. Bitmap - 말 그대로 해당 정보를 비트에 매핑시키는 자료구조. 비트로 정보를 저장하기에 공간 복잡도 측면에서 매우 효율적임. 구분해야 할 자료가 많지 않을 때는 이만큼 효율적인 것도 없으나 구분해야 할 서로 다른 자료가 많으면 많을수록 복잡해지는 측면이 있음.
Anonymous Page
vm_alloc_page_with_initializer => 커널이 새 페이지 요청을 수신할 때 호출됩니다. 이니셜라이저는 페이지 구조를 할당하고 페이지 유형에 따라 적절한 이니셜라이저를 설정하여 새 페이지를 초기화하고 컨트롤을 다시 사용자 프로그램으로 반환합니다 1. Anonymous page: 어떤 파일과도 연결되지 않은 페이지 -> anonymous page는 파일에 기반하고 있지 않은 페이지이기에 0으로 초기화되어 있다. 2. File-backed page: 파일과 매핑된 페이지(즉, 페이지 안에 파일이 들어있는) anon 페이지는 커널로부터 프로세스에게 할당된 일반적인 메모리 페이지를 뜻한다. 즉, heap을 거치지 않고 할당받은 메모리 공간이다. 사실상 이 힙 역시도 anonymous page에 속한다고 보면 된다. 힙은 일종의 거대한 anonymous page의 집합으로 취급하면 될듯. heap 뿐만 아니라 stack을 사용할 때 역시 anonymous page를 할당받아서 쓴다.
Page fault
page fault가 일어나기전 load_segment에서 if (!vm_alloc_page_with_initializer (VM_ANON, upage, writable, lazy_load_segment, container)) 호출 해당 initailizer에서 vm_type에 따라 initializer를 세팅 -> 이 initializer는 page fault가 발생했을 때 작동 page_fault (struct intr_frame *f) -> vm_try_handle_fault (f, fault_addr, user, write, not_present) -> vm_claim_page(addr) -> vm_do_claim_page (page) -> swap_in (page, frame->kva) -> -> uninit = .swap_in = uninit_initialize uninit->page_initializer (page, uninit->type, kva) && (init ? init (page, aux) : true); 여기서의 init 은 lazy_load_segment, page_initializer는 type에 따라 설정한 initializer -> anon = .swap_in = anon_swap_in, -> file = .swap_in = file_backed_swap_in,
Lazy loading
지연 로딩은 메모리 로딩이 필요할 때까지 지연되는 설계입니다. 페이지가 할당됩니다. 즉, 해당 페이지 구조가 있지만 전용 물리적 프레임이 없으며 페이지의 실제 콘텐츠가 아직 로드되지 않았습니다. 콘텐츠는 정말 필요한 경우에만 로드되며 이는 페이지 오류로 표시됩니다. 지연 로딩에서는 프로세스가 실행을 시작할 때 즉시 필요한 메모리 부분만 메인 메모리에 로드됩니다. 이는 모든 바이너리 이미지를 한 번에 메모리에 로드하는 즉시 로딩에 비해 오버헤드를 줄일 수 있습니다.
Stack Growth
VM에서 동작하는 케이스가 아닌 경우, setup_stack은 최소 크기의 스택을 생성하는데 이는 0으로 초기화된 한 페이지를 user stack으로 할당해주는 방식이었다. 즉, 이제부터는 page fault에 의해 스택 크기를 동적으로 할당해줄 것이다. 왜 stack을 동적으로 할당하는 게 스택 사이즈를 고정하는 것보다 좋을까? 미리 고정 할당해놓고 있으면 추가로 그때그때 얼마나 스택이 필요할지 알 수도 없을 뿐더러 다른 곳에 써야 할 수도 있을 빈 공간을 스택을 위해 공간 할당 해놓게 되면 빈 자리만 차지하니 효율성 측면에서도 나쁘다. 즉, 메모리 낭비 이 페이지에 접근하는 과정에서 스택에 정보가 쌓이다가 우리가 할당해준 영역 밑으로 rsp(스택 포인터)가 접근하면 page fault가 뜰 것이다. 우리가 할당해주지 않은 페이지이니까. 이때가 바로 stack growth가 발생하는 시점이 된다. 정확히는 stack growth에 대한 page fault가 발생하면 스택 사이즈를 증가(= 추가로 페이지를 할당)한다. 유저 가상 주소 공간에서 page fault가 발생하는 케이스 혹은 시스템 콜에서는 해당 프로세스의 인터럽트 프레임 내 rsp 멤버값을 그대로 사용해도 된다. 왜냐면 이 상황은 각각 유저 프로세스 <-> 운영체제 사이로만 왔다갔다 하지 다른 사용자 프로세스로 cpu가 넘어가는 케이스가 아니기 때문이다. 그렇기 때문에 page fault가 발생해 모드가 전환되면 유저 프로그램의 스택 포인터 값(유저 스택 포인터)은 intr_frame->rsp에 저장되어 page fault handler나 system call handler에 인자로 전달된다. 하지만 유효하지 않은 페이지에 접근해 page fault가 나는 케이스도 있다고 Gitbook에서 소개하는데, 이 경우는 커널 주소 공간에서 page fault가 발생했을 때이다. 문제는 이 경우에는 intr_frame으로부터 rsp(유저 스택 포인터)값을 전달받지 못하게 된다. 유저 프로세스가 돌고 있는 상황에서 page fault가 떴을 때는 해당 유저 스택 포인터 값을 intr_frame 내 rsp 멤버에 저장하지만, 커널 프로세스가 돌고 있는 상황에서 page fault가 뜨면 이때는 애초에 커널 영역이니 유저 영역의 스택 포인터를 intr_frame에 옮겨주는 과정이 없다. 그러니 이 케이스에서 page_fault()로 전달받은 intr_frame을 뒤져봤자 유저 스택 포인터를 찾을 수 없고 엉뚱한 값을 전달받게 된다. 이를 위해 GItbook에서 제시하는 방식은 유저 프로세스가 생성되고 커널로 최초의 transition이 일어났을 때 struct thread 구조체에 해당 rsp 주소값(유저 스택 포인터)을 구조체 내 멤버값으로 저장하는 방식을 설명한다. 마치 tss 내 rsp0가 커널 스택 포인터 값을 항상 들고 있는 것과 같은 맥락이라 볼 수 있다.
1. 인터럽트 프레임의 rsp 멤버가 유저 스택을 가리키고 있다면 이 스택 포인터를 그대로 사용해도 괜찮다. 하지만 인터럽트 프레임의 rsp 멤버가 커널 스택을 가리키고 있다면(커널 프로세스에서 page fault가 뜬 경우가 이에 해당한다) 우리가 원하는 것은 유저 스택을 키우는 것이니 앞서 첫번째로 유저 -> 커널로 transition이 일어날 때 thread 구조체 내 rsp 멤버로 저장하는 방식을 이용해 여기서 rsp 값을 가져온다. 2. fault가 발생한 주소가 유저 스택 내에 있는지 (rsp_stack-8 <= addr && USER_STACK - 0x100000 <= addr && addr <= USER_STACK) 유저 프로그램은 이 프로그램이 스택 포인터 아래 영역의 스택에 write을 할 때 버그가 생긴다. 왜냐면 실제 OS는 스택에 데이터를 수정하는 시그널을 전달하기 위해 언제든지 프로세스에 인터럽트를 걸 수 있기 때문이다. 하지만, x86-64에서 PUSH 명령어는 스택 포인터 위치를 조정하기 전에 접근 권한을 체크하는데, 이는 스택 포인터 아래 8바이트 위치에서 page fault를 일으킨다. 스택에는 함수의 매개변수, 지역 변수 혹은 caller에 의해 호출된 callee 함수가 들어간다. 스택에서 push 인스트럭션이 작동하는 방식은 스택 포인터 위치를 8바이트 내리고 원래 스택 포인터 위치와 8바이트 내린 스택 포인터 사이에 주소값을 넣는 형태이다. 아래 그림을 보면 스택 top이 8바이트 아래로 내려가고 그 사이에 0x123이 들어간 것을 확인할 수 있다. 여기서 만약 해당 주소가 0x100보다 아래에 있다면 어떻게 될까? push 인스트럭션은 한 번에 8바이트씩만 내려가며 원래 위치와 8바이트 내려간 위치 사이에 주소값을 삽입하는 방식인데 그 아래에 주소값이 들어가게 되면 이는 정상적인 push 인스트럭션이 아니라고 간주할 수 있다. 이 경우에는 해당 주소값이 stack 절대 크기 영역 내에 있더라도 허용하면 안되는 케이스이므로 이 역시 차단한다.
Memory Mapped Files
특정 파일과 매핑된 페이지 (file-backed page) memory-mapped file은 곧 file-backed page와 연결된 파일을 뜻한다. 이 페이지 안의 내용은 이미 디스크에 존재하는 파일의 데이터를 복제하기 때문에 page fault가 발생했을 때 즉시 디스크->프레임에 할당된다. 메모리가 해제되거나 swap-out되면 메모리 내 변경 사항은 파일로 반영된다.
void *mmap (void *addr, size_t length, int writable, int fd, off_t offset); 파일 디스크립터 fd로 오픈한 파일을 offset byte 위치에서부터 시작해 length 바이트 크기만큼 읽어들여 addr에 위치한 프로세스 가상 주소 공간에 매핑한다. 전체 파일은 페이지 단위로 나뉘어 연속적인 가상 주소 페이지에 매핑된다. 즉, mmap()은 메모리를 페이지 단위로 할당받는 시스템 콜이다. 실패상황 1) 파일의 시작점(offset)이 page-align되지 않았을 때 이는 빠른 접근을 위한 제약사항이다. spt_find_page()를 이용해 가상 주소에 접근하면 그 주소가 포함된 페이지만 리턴으로 받는다. OS는 단일 주소 위치가 아닌 가상 메모리 내 페이지 단위로 접근해 정보를 읽어들인다. 파일 역시 페이지 단위로 load/save되는 것을 위의 mmap에 대한 설명을 통해 알 수 있다. 그러니 시작점이 page-align(파일 시작점이 PGSIZE의 배수와 일치해야 페이지의 제일 윗부분부터 채워질테니)되지 않으면 페이지 단위로 접근하지 못하는 상황이 발생(페이지 윗 부분이 떠버림) 2) 가상 유저 page 시작 주소가 page-align되어있지 않을 때 3) 매핑하려는 페이지가 이미 존재하는 페이지와 겹칠 때(==SPT에 존재하는 페이지일 때) 4) 페이지를 만들 시작 주소 addr이 NULL이거나 파일 길이가 0일 때 5) 콘솔 입출력과 연관된 파일 디스크립터 값(0: STDIN, 1:STDOUT)일 때
mmap 과 malloc의 차이점 mmap vs malloc
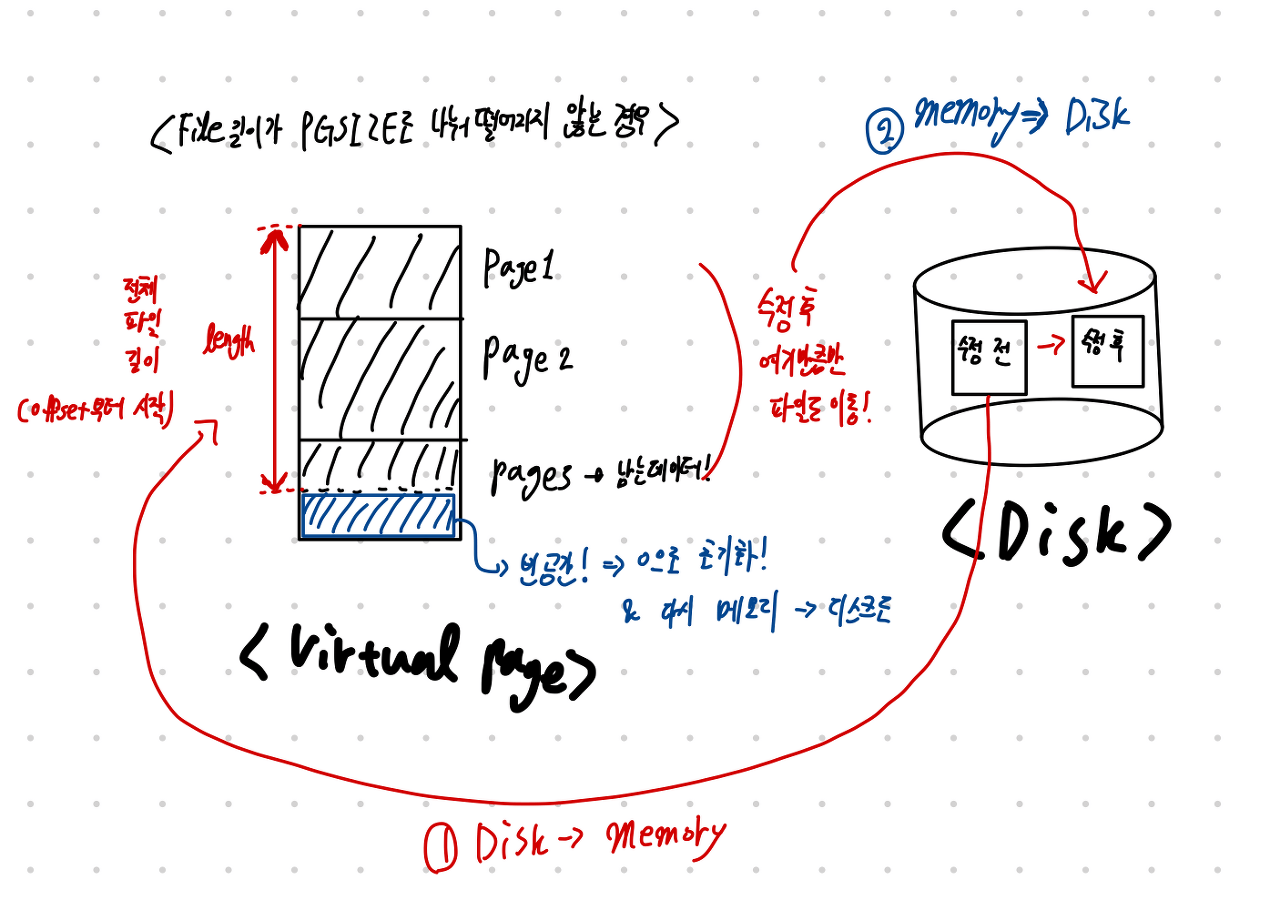
0으로 채워준 이유 => 해당 작업 중 기존에 디스크에 있던 파일 정보를 가지고 있는 페이지 일수도 있기 때문에 0으로 채워준다. 디스크에 swap_out을 할 때는 file_length만큼만 넣어준다. 기존에 있는 파일이 수정되면 안되니까 이때 페이지단위로 움직이기 때문에 해당 페이지는 수정된 데이터와 기존에 있던 데이터를 동시에 가지고 있을 것이다. 이 페이지를 다시 swap_in 할때는 offset 과 length로 필요한 부분만 데이터를 읽고 쓰게된다. 또한 메모리에 올려서 vm 과 pm이 사용할 단위가 page이고 swap_out될때 즉 disk에는 보관 단위가 sector단위이기에 length 만큼 swap_out이 가능하다.
void * do_mmap (void *addr, size_t length, int writable, struct file *file, off_t offset); do_mmap()은 실질적으로 가상 페이지를 할당해주는 함수이다. 인자로 받은 addr부터 시작하는 연속적인 유저 가상 메모리 공간에 페이지를 생성해 file의 offset부터 length에 해당하는 크기만큼 파일의 정보를 각 페이지마다 저장한다. 프로세스가 이 페이지에 접근해서 page fault가 뜨면 물리 프레임과 매핑(이때 claim을 사용한다)해 디스크에서 파일 데이터를 프레임에 복사한다.
Mummap
munmap() 함수는 우리가 지우고 싶은 주소 addr 로부터 연속적인 유저 가상 페이지의 변경 사항을 디스크 파일에 업데이트한 뒤, 매핑 정보를 지운다. 여기서 중요한 점은 페이지를 지우는 게 아니라 present bit을 0으로 만들어준다는 점이다. 따라서 munmap() 함수는 정확히는 지정된 주소 범위 addr에 대한 매핑을 해제하는 함수라고 봐야겠다. 이때 인자로 들어오는 주소 addr은 아직 매핑이 해제되지 않은 같은 프로세스에서 mmap 호출에 의해 반환된 가상 주소여야 한다. 뭔 말이냐, 매핑을 해제하려는 페이지는 mmap()으로 할당된 가상 페이지여야 하며, 이 페이지는 mmap()으로 할당할 당시의 유저 프로세스와 동일한 프로세스여야 한다는 뜻. 다른 프로세스가 갑자기 와서 자기가 mmap()으로 페이지 할당해주지도 않았는데 munmap()을 하면 안되지 않겠나. Dirty Bit Dirty bit은 해당 페이지가 변경되었는지 여부를 저장하는 비트이다. 페이지가 변경될 때마다 이 비트는 1이 되고, 디스크에 변경 내용을 기록하고 나면 해당 페이지의 dirty bit는 다시 0으로 초기화해야 한다. 즉, 변경하는 동안에 dirty bit가 1이 된다. 페이지 교체 정책에서 dirty bit이 1인 페이지는 디스크에 접근해 업데이트한 뒤 매핑을 해제해줘야 하기 때문에 비용이 비싸다. (디스크 한 번 갔다 와야 하니까). 따라서 페이지 교체 알고리즘은 dirty page 대신 변경되지 않은 상태인 깨끗한(?) 페이지를 내보내는 것을 선호한다. 이 경우는 그냥 swap out만 해주면 되니까. Present Bit 해당 페이지가 물리 메모리에 매핑되어 있는지 아니면 swap out되었는지를 가리킨다. Swap in/out에서 더 다룰 것. present bit이 1이면 해당 페이지가 물리 메모리 어딘가에 매핑되어 있다는 말이며 0이면 디스크에 내려가(swap out)있다는 말이다. 이렇게 present bit이 0인, 물리 메모리에 존재하지 않는 페이지에 접근하는 과정이 file-backed page에서의 page fault이다.
pml4_is_dirty() 페이지의 dirty bit이 1이면 true를, 0이면 false를 리턴한다. bool pml4_is_dirty (uint64_t *pml4, const void *vpage) { uint64_t *pte = pml4e_walk (pml4, (uint64_t) vpage, false); return pte != NULL && (*pte & PTE_D) != 0; } file_write_at() 물리 프레임에 변경된 데이터를 다시 디스크 파일에 업데이트해주는 함수. buffer에 있는 데이터를 size만큼, file의 file_ofs부터 써준다. off_t file_write_at (struct file *file, const void *buffer, off_t size, off_t file_ofs) { return inode_write_at (file->inode, buffer, size, file_ofs); } pml4_set_dirty() 인자로 받은 dirty의 값이 1이면 page의 dirty bit을 1로, 0이면 0으로 변경해준다. void pml4_set_dirty (uint64_t *pml4, const void *vpage, bool dirty) { uint64_t *pte = pml4e_walk (pml4, (uint64_t) vpage, false); if (pte) { if (dirty) *pte |= PTE_D; else *pte &= ~(uint32_t) PTE_D; if (rcr3 () == vtop (pml4)) // CR3 : Page Directory Base Register invlpg ((uint64_t) vpage); // INVLPG : Invalidate TLB Entries } } pml4_clear_page() 페이지의 present bit 값을 0으로 만들어주는 함수 void pml4_clear_page (uint64_t *pml4, void *upage) { uint64_t *pte; ASSERT (pg_ofs (upage) == 0); ASSERT (is_user_vaddr (upage)); pte = pml4e_walk (pml4, (uint64_t) upage, false); if (pte != NULL && (*pte & PTE_P) != 0) { *pte &= ~PTE_P; // Present bit(0x1) mask off if (rcr3 () == vtop (pml4)) // CR3 : Page Directory Base Register invlpg ((uint64_t) upage); // INVLPG : Invalidate TLB Entries } }
1: mmap으로 페이지를 할당받으면 힙/스택 중 어느 공간에 페이지가 할당되는가?
결론부터 말하면 mmap으로 페이지를 할당받으면 힙도 스택도 아닌 공간에 할당된다. 아래그림 에서도 나와있듯 mmap은 file의 offset 위치부터 length 길이만큼 읽어들여 가상 메모리에 매핑한다. 이때 주의할 점은 첫번째로 매핑할 때는 물리 프레임에는 올리지 않는다는 점.
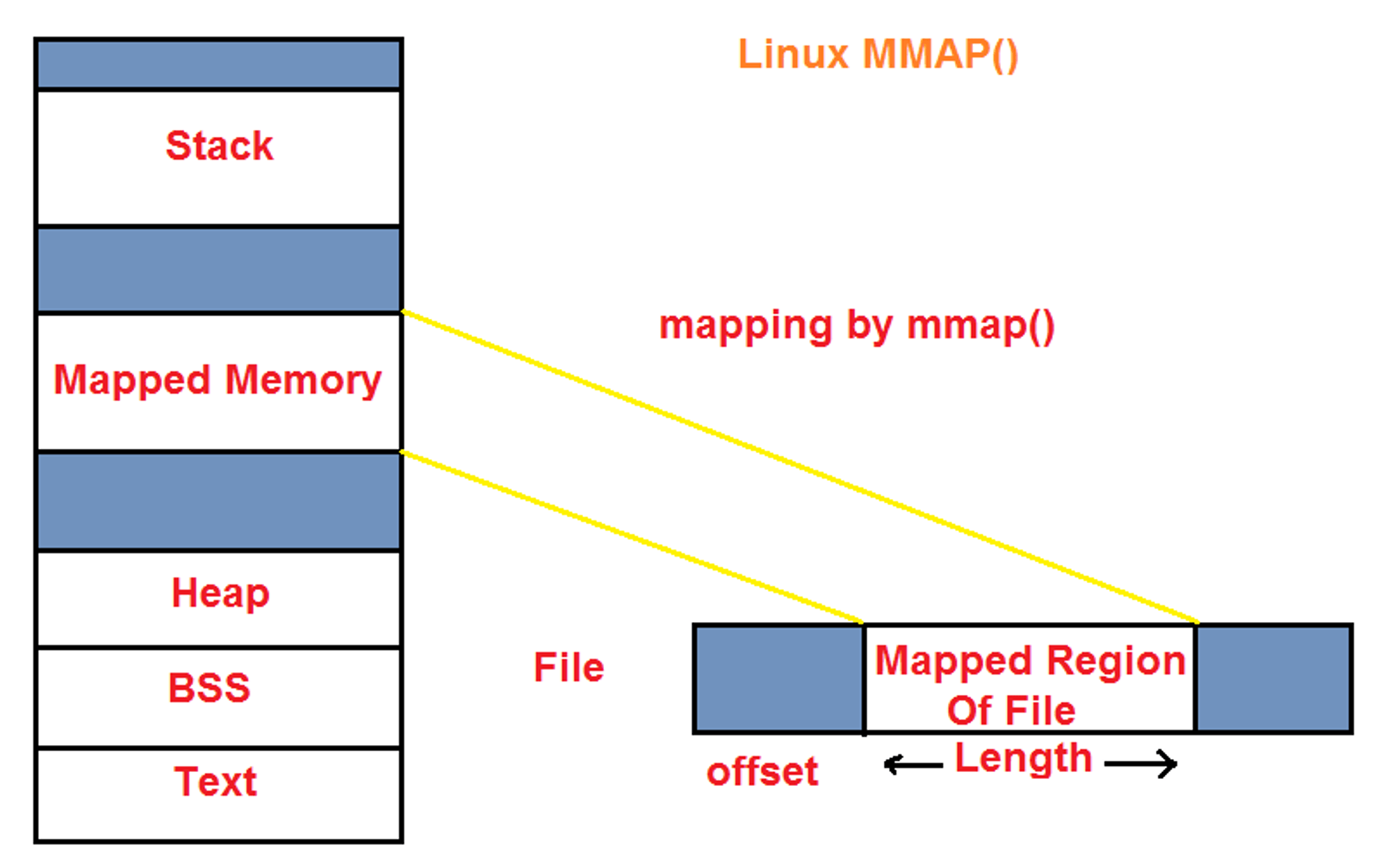
이 역시 malloc()과 차이라고 할 수 있는데, malloc()은 힙 공간에 인자로 넣어주는 사이즈만큼의 공간을 할당한다.
공부하면서 느끼는 건데, malloc()과 mmap()은 아예 다르다고 봐야 할듯. malloc()은 응용 프로그램이 런타임에 메모리를 동적으로 할당해달라고 요청하는 함수이고(이는 heap에서 생성됨 - anonymous page가 할당), mmap()은 정해진 일련의 가상 페이지를 정적으로 요청하는 함수(힙도 스택도 아닌 미할당 공간 중 페이지를 생성 - file-backed page)이다.
1. 맨 처음 파일을 가상 페이지에 할당할 때 (load_segment가 이를 시행) Pintos 부팅 -> init.c 실행 -> ... ->run_actions() -> run_task() -> process_create_initd() -> initd() -> spt_init()으로 spt 테이블 초기화되고 -> process_exec() -> load(): 입력으로 넣어준 file_name에 해당하는 실행 파일을 현재 스레드에 load -> load_segment(): container 구조체 생성해 해당 구조체에 파일 메타데이터(파일 구조체, page_read_byte, offset)를 저장한 뒤 vm_alloc_page_with_initializer()를 호출 더보기 ->vm_alloc_page_with_initializer(): 해당 파일 형태(uninit/anonymous/file-backed)에 맞게 초기화해준다. 여기까지가 처음 해당 파일을 호출했을 때 파일이 가상 페이지에 할당되는 과정이며 해당 파일 자체 정보는 물리 프레임에는 1도 할당되지 않는다. (관련 메타데이터는 malloc 호출해서 heap에 저장 - 함수가 호출되는 동안만 잠깐 저장할 거면 stack에 하겠지만 지금 상황은 나중에 해당 페이지에 프로세스가 접근할 때까지 해당 정보를 들고 있어야 하니 heap에 저장할 필요가 있다! - malloc) 2. 프로세스가 페이지만 할당되어 있는 가상 주소에 접근한 상황 발생 exception_init(): exception 발생: handler가 작동한다. ->page_fault(): 해당 페이지에 정보가 있다고 해서 가봤더니 정보가 없다. 그러면 page fault가 발동한다. ->vm_try_handle_fault(): 먼저 유저 스택 포인터를 가지고 온다. -> vm_claim_page(): 그 다음, 해당 인자로 받은 가상 주소에 해당하는 페이지를 spt 테이블로부터 들고온다. ->vm_do_claim_page() -> vm_get_frame(): 물리 프레임을 할당받아 온다. -> install_page(): 위에서 받아온 물리 프레임과 가상 페이지를 연결한다.
Swap_in
메모리 스와핑은 물리적 메모리 사용을 최대화하기 위한 메모리 회수 기술입니다. 주 메모리의 프레임이 할당되면 시스템은 사용자 프로그램의 메모리 할당 요청을 더 이상 처리할 수 없습니다. 한 가지 해결책은 현재 디스크에 사용되지 않는 메모리 프레임을 교체하는 것입니다. 이렇게 하면 일부 메모리 리소스가 해제되고 다른 응용 프로그램에서 사용할 수 있습니다. 스와핑은 운영 체제에서 수행됩니다. 시스템이 메모리 부족을 감지했지만 메모리 할당 요청을 받으면 스왑 디스크로 제거할 페이지를 선택합니다. 그런 다음 메모리 프레임의 정확한 상태가 디스크에 복사됩니다. 프로세스가 스왑 아웃된 페이지에 액세스하려고 시도하면 OS는 정확한 콘텐츠를 메모리로 다시 가져와 페이지를 복구합니다.
anon_page -> swapping 위해 swap_disk(in disk) swap_table(in ram) 세팅 swap_table은 bitmap으로 구성되어있으며, swap_table의 index 1개는 swap_slot을 의미하며 swap_slot = (swap_sector * 8 == Page)
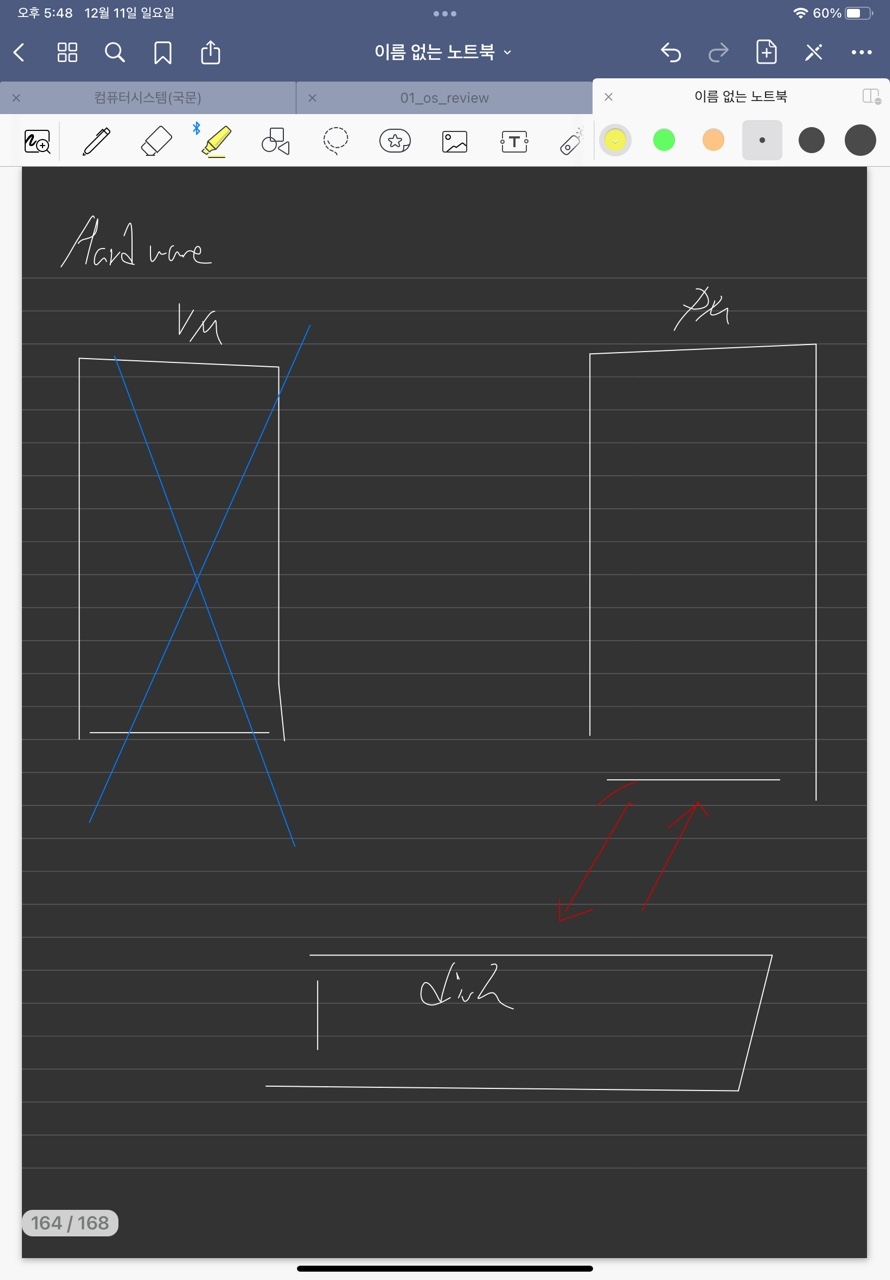
하드웨어적 관점에서는 PM과 disk 간에 파일을 읽고 쓴다. 즉 가상메모리 자체는 실존하는 것이 아니고 process<-> OS 입장에서 사용하는 것이다.

process 입장에서는 spt 로 pm과 매핑되어 있기 때문에 disk에서 직접적으로 주고받는다고 착각을 하게 된다.
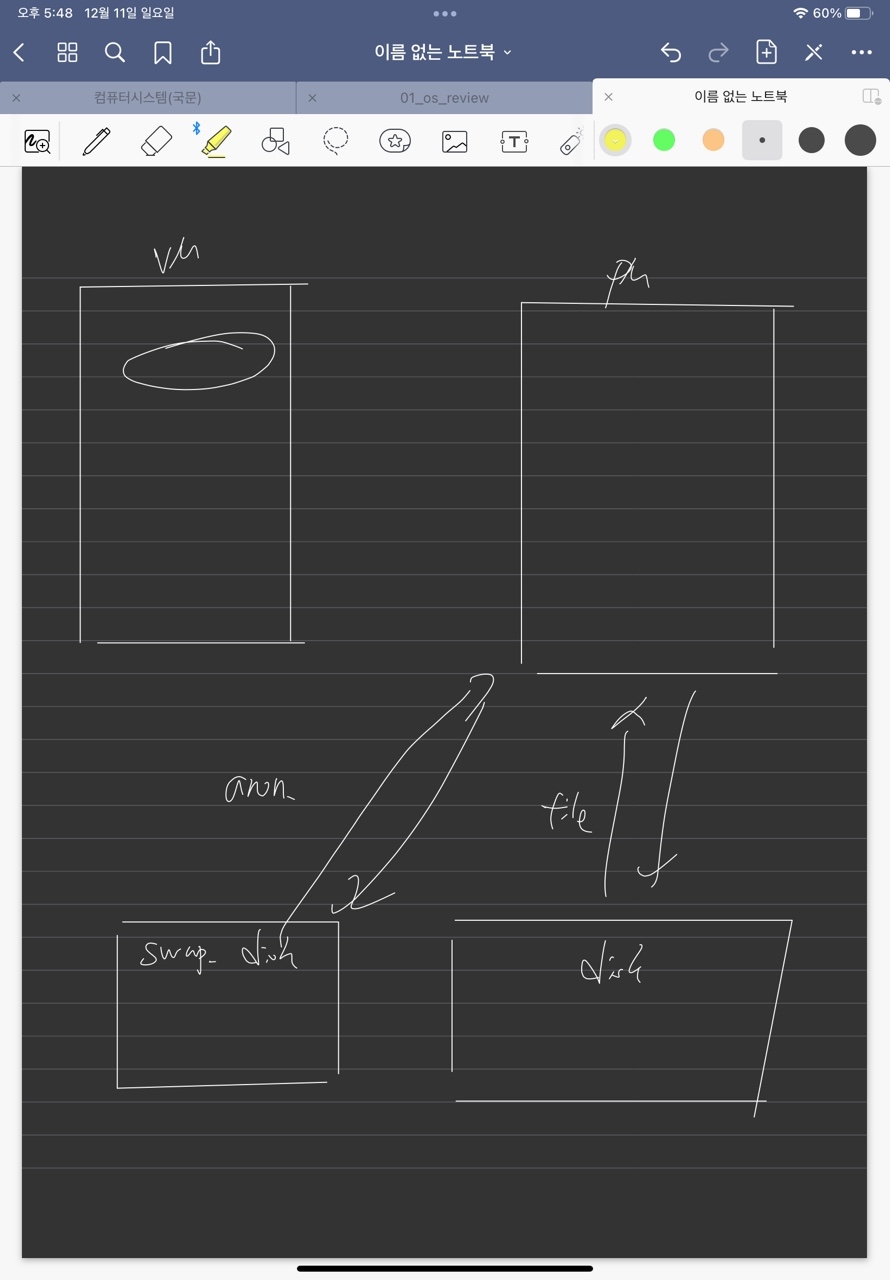
swap_disk는 disk의 파티션으로 bitmap으로 구성되어 있으며, anon_page에 대해서 swap_in/out을 실행한다. file_page는 disk(ssd or hdd)에서 swap_in/out을 실행한다.
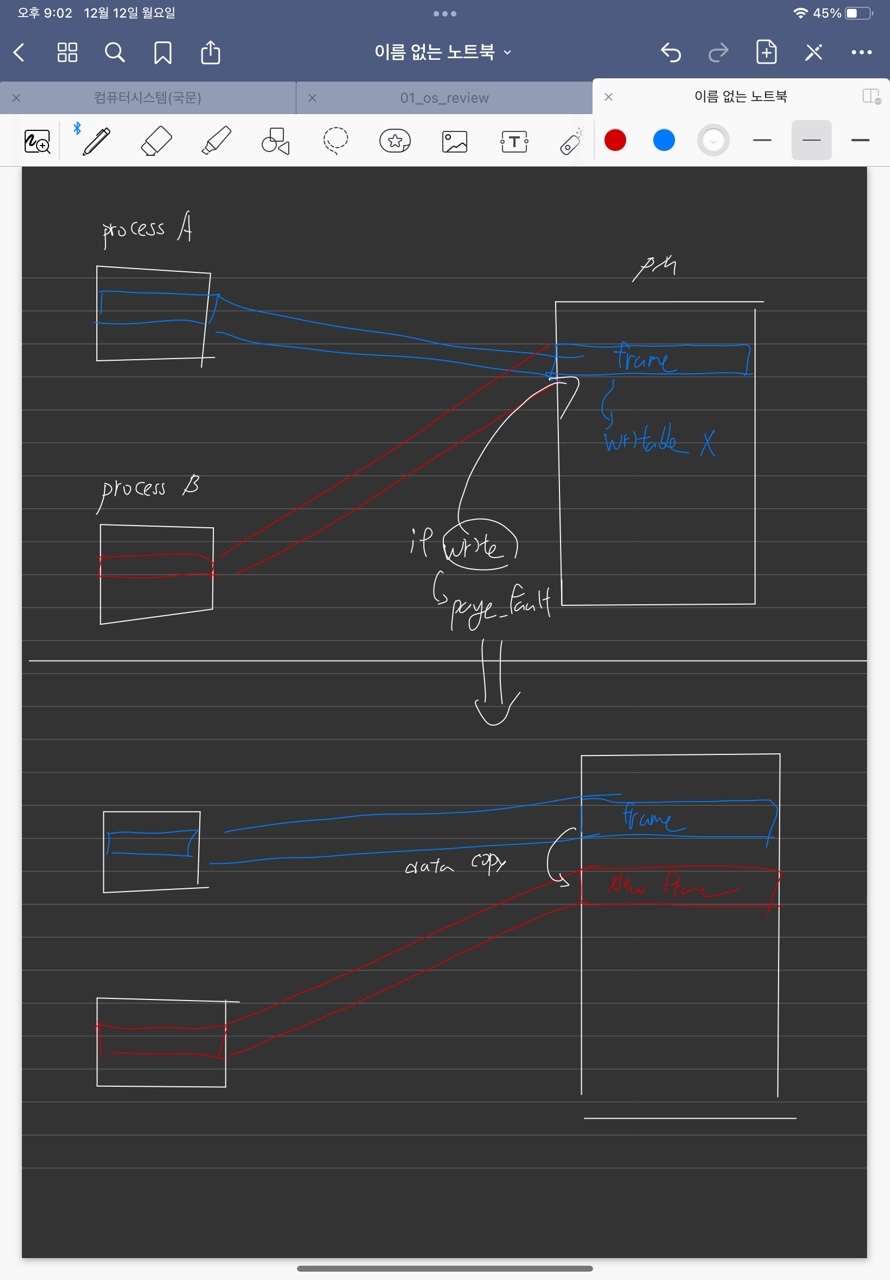
(Extra)Copy-On-Write
IN GIT-BOOK Copy-on-write는 물리적 페이지의 동일한 인스턴스를 사용하여 더 빠른 복제 작업을 허용하는 리소스 관리 기술입니다. 일부 리소스가 여러 프로세스에서 사용 중인 경우 일반적으로 각 프로세스에는 충돌이 발생하지 않도록 자체 리소스 복사본이 있어야 합니다. 그러나 리소스가 수정되지 않고 읽기만 되는 경우 물리적 메모리에 여러 복사본이 있을 필요가 없습니다. 예를 들어 를 통해 새 프로세스가 생성되었다고 가정합니다 fork. 자식은 데이터를 가상 주소 공간에 복제하여 부모의 리소스를 상속해야 합니다. 일반적으로 가상 메모리에 콘텐츠를 추가하려면 물리적 페이지 할당, 프레임에 데이터 쓰기, 페이지 테이블에 가상->물리 매핑 추가가 포함됩니다. 이러한 단계는 상당한 시간이 소요될 수 있습니다. 그러나 copy-on-write 기술을 사용하면 리소스의 새 복사본에 대해 새 물리적 페이지를 할당하지 않습니다. 이는 기술적으로 콘텐츠가 물리적 메모리에 이미 존재하기 때문입니다. 따라서 가상 주소가 이제 자식의 메모리 공간에 있는 자식 프로세스의 페이지 테이블에 가상->물리적 매핑만 추가합니다. 그런 다음 부모와 자식은 동일한 물리적 페이지에서 동일한 데이터에 액세스합니다. 그러나 여전히 별도의 가상 주소 공간을 통해 격리되어 있으며 OS만이 동일한 프레임을 참조하고 있음을 알고 있습니다. 프로세스 중 하나가 공유 리소스의 내용을 수정하려고 할 때만 새 물리적 페이지에 별도의 복사본을 만듭니다. 따라서 실제 복사 작업은 첫 번째 쓰기로 연기됩니다.
위 깃북의 내용을 정리해보면 기존에 copy방식은 새로운 프레임을 할당받고 매핑하고, 데이터를 써주는 것 까지해야한다. 하지만 read-only인 경우 할당할 필요 없이 부모 페이지와 동일한 frame 주소를 갖도록 만들어 메모리와 시간절약을 한다. 해당 frame과 연결된 쓰기 접근을 할 경우 부모와 fork 된 페이지 모두 page_fault를 일으키도록 write에 대한 권한이 없도록 페이지 테이블에 세팅한다. 해당 frame에 write를 시도할 경우 page_fault가 발생하고, 그때 프레임을 할당하고, 데이터를 복사하고 원래의 writable상태를 페이지 테이블에 세팅해준다.
댓글을 불러오는 중입니다.

정글에서 살아남기 Week 11
PintOS Virtual Memory(1)

정글에서 살아남기 Week 13
PintOS FileSystem